SQL의 개념
데이터베이스 시스템에서 자료를 처리하는 용도로 사용되는 구조적 데이터 질의 언어
SQL 문법의 종류
1) DDL - 데이터 정의어
- 데이터가 저장되는 테이블이나 각종 개체들을 정의하는 데 사용되는 명령
- CREATE, ALTER, DROP, RENAME, TRUNCATE
2) DML - 데이터 조작어
- 데이터베이스 내의 데이터를 조작 ( 추출, 생성, 수정, 삭제 )하는 명령
- SELECT, INSERT, UPDATE, DELETE
3) DCL - 데이터 제어어
- 데이터베이스에 접근하고, 객체들을 사용하도록 권한을 주고 회수하는 명령
- GRANT, REVOKE
4) TCL - 트랜잭션 제어어
- 논리적인 작업의 단위를 묶어 이에 의해 조작된 결과를 작업 단위별로 제어하는 명령어
- COMMIT, ROLLBACK, SAVEPOINT
DDL - 데이터 정의어
데이터가 저장되는 테이블이나 각종 개체들을 정의하는 데 사용되는 언어
1) CREATE
- 새로운 데이터베이스 생성
CREATE DATABASE school;- 새로운 테이블 생성
CREATE TABLE students (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
email VARCHAR(100) UNIQUE
);- INDEX 생성
CREATE INDEX idx_students_name ON students (name);- VIEW 생성
CREATE VIEW view_students AS
SELECT id, name, age
FROM students
WHERE age >= 18;
2) ALTER
- 컬럼 추가
ALTER TABLE students
ADD address VARCHAR(255);- 컬럼 수정
ALTER TABLE students
MODIFY COLUMN name VARCHAR(100) NOT NULL;- 컬럼 삭제
ALTER TABLE table_name
DROP COLUMN column_name;- 인덱스 변경
// 인덱스 이름변경 - RENAME TO
ALTER INDEX idx_customer_name RENAME TO idx_cust_name;
// 인덱스 다시 빌드 ( 성능 최적화, 테이블의 변경 사항 반영 ) - REBUILD
ALTER INDEX idx_customer_name REBUILD;
// 인덱스 사용 불가능한 상태로 설정 - UNUSABLE
ALTER INDEX index_name UNUSABLE;
3) DROP : 삭제 명령어
- 테이블 삭제
DROP TABLE students;
4) TRUNCATE : 데이터 삭제 명령어로 테이블의 모든 데이터를 삭제, 테이블의 구조는 유지
TRUNCATE TABLE students;
제약 조건 적용
| 제약 조건 | 설명 |
| PRIMARY KEY | 테이블의 기본키를 정의 기본으로 NOT NULL, UNIQUE 제약조건이 포함 |
| FOREIGN KEY | 외래키를 정의 참조 대상을 테이블이름으로 명시 참조 무결성 위배 상황 발생 시 처리 방법으로 옵션 지정 가능 ( CASCADE, RESTRICT ) |
| UNIQUE | 테이블 내에서 열은 유일한 값을 가져야 함 테이블 내에서 동일한 값을 가져서는 안되는 항목에 지정 |
| NOT NULL | 테이블 내에서 관련 열의 값은 NULL일 수 없음 필수 입력 항목에 대해 제약 조건으로 설정 |
| CHECK | 개발자가 정의하는 제약 조건 상황에 따라 다양한 조건 설정 가능 |
++ CHECK 제약조건은 데이터베이스 테이블에서 특정 조건을 만족하는 데이터만 입력되도록 제한하는 제약조건으로
이를 사용하면 데이터 무결성을 유지할 수 있다.
- 특정 컬럼의 값이 정의된 조건을 만족하는 조건을 설정해야하고, 데이터 삽입 또는 업데이트 시 조건을 확인하여 유효하지 않은 데이터 입력을 방지한다.
- 비교연산자와 논리 연산자를 사용하여 복잡한 조건을 설정할 수 있다.
- 예시
CREATE TABLE employees (
employee_id NUMBER PRIMARY KEY,
first_name VARCHAR2(50),
last_name VARCHAR2(50),
salary NUMBER,
CHECK (salary > 0)
);=> employee 테이블의 salary 컬럼에 대해 0보다 큰 값만 입력되 수 있도록 제한하고 있다.
DML - 데이터 조작어
데이터베이스에 대해 데이터 검색, 등록, 삭제, 수정을 위한 데이터베이스 언어
1) INSERT : 테이블에 데이터를 삽입하는데 사용, 컬럼의 순서와 값의 순서가 같아야 해당 컬럼으로 데이터가 추가됨 !
-- 'employees' 테이블에 새로운 직원 데이터를 삽입
INSERT INTO employees (employee_id, first_name, last_name, salary)
VALUES (1, 'John', 'Doe', 50000);
2) SELECT : 하나 또는 그 이상의 테이블에서 데이터를 추출하는 SQL 데이터 조작 언어
사용구문
- WHERE : 조건에 맞는 데이터를 지정
- GROUP BY : 특정 속성을 그룹으로 만들어서 집계 함수를 사용
- HAVING : GROUP BY 절에 정의된 조건
- ORDER BY : 반환되는 행의 순서를 지정
-- 'employees' 테이블에서 모든 직원의 데이터를 조회
SELECT * FROM employees;
-- 'employees' 테이블에서 'salary'가 40000 이상인 직원의 'first_name'과 'salary'를 조회
SELECT first_name, salary
FROM employees
WHERE salary >= 40000;
3) UPDATE : 테이블에 있는 데이터를 갱신, WHERE절이 생략된 경우 모든 행이 갱신
-- 'employees' 테이블에서 'employee_id'가 1인 직원의 급여를 수정
UPDATE employees
SET salary = 55000
WHERE employee_id = 1;
4) DELETE : 테이블에 있는 일부 데이터를 직접 삭제, WHERE 절을 생략했을 경우 모든 행이 삭제
-- 'employees' 테이블에서 'employee_id'가 1인 직원의 데이터를 삭제
DELETE FROM employees
WHERE employee_id = 1;
DCL - 데이터 제어어
: 데이터베이스에 접근하거나 객체에 권한을 주는 등의 역할을 하는 언어
1) GRANT : 데이터베이스 사용자에게 권한을 부여하는 명령
+ WITH GRANT OPTION : 지정된 권한을 다른 유저에게 부여할 수 있도록 함
-- 'john' 사용자에게 'employees' 테이블에 대한 SELECT 권한을 부여
GRANT SELECT ON employees TO john;
-- 'john' 사용자에게 'employees' 테이블에 대한 INSERT 및 UPDATE 권한을 부여
GRANT INSERT, UPDATE ON employees TO john WITH GRANT OPTION;
2) REVOKE : 데이터베이스 사용자에게서 권한을 회수하는 명령
-- 'john' 사용자에게 'employees' 테이블에 대한 SELECT 권한을 철회
REVOKE SELECT ON employees FROM john;
-- 'john' 사용자에게 'employees' 테이블에 대한 INSERT 및 UPDATE 권한을 철회
REVOKE INSERT, UPDATE ON employees FROM john;
TCL - 트랜잭션 제어어
1) COMMIT : 트랜잭션 처리가 정상적으로 종료되어 트랜잭션이 수행한 변경 내용을 데이터베이스에 반영하는 연산
내용을 변경한 트랜잭션이 완료되면 그 트랜잭션에 의해 데이터베이스는 새롭게 일관된 상태로 변경되며, 이 상태는 시스템 오류가 발생하더라도 취소되지 않는다.
2) ROLLBACK : 데이터 변경 사항이 취소되어 데이터의 이전 상태로 복구
3) SAVEPOINT : 저장점을 정의하면 롤백 시에 트랜잭션에 포함된 전체 작업을 롤백하는 것이 아니라 현 시점에서 SAVEPOINT까지 트랜잭션의 일부만 롤백
집합연산자
| 종류 | 설명 |
| UNION | 여러 개의 SQL문의 결과에 대한 합집합 결과에서 중복된 모든 행은 하나의 행으로 출력 |
| UNION ALL | 여러 개의 SQL문의 결과에 대한 합집합 중복된 행도 그대로 결과로 표시 |
| INTERSECT | 여러 개의 SQL문의 결과에 대한 교집합 중복되 행은 하나의 행으로 출력 |
| EXCEPT ( MINUS ) | 앞의 SQL문의 결과에서 뒤의 SQL문의 결과에 대한 차집합 중복된 행은 하나의 행으로 출력 |
JOIN
두 개 이상의 테이블을 결합하여 데이터를 검색하는 방법
조인 연산자를 사용해 관련 있는 컬럼 기준으로 행을 합쳐주는 연산
종류
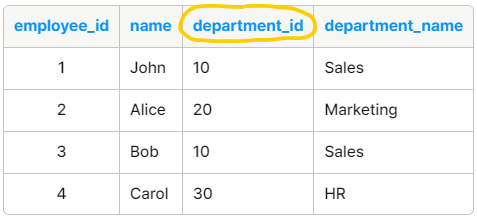
1) 내부 조인 ( Inner Join )
- 테이블에 존재하는 데이터 중에 공통된 데이터만 추출
- 예시
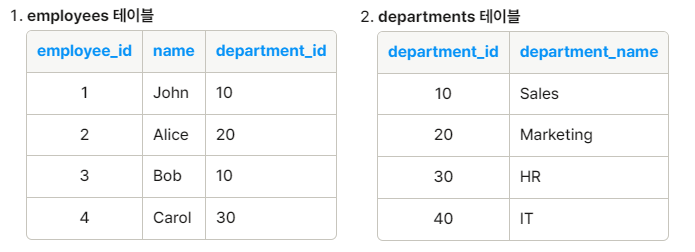
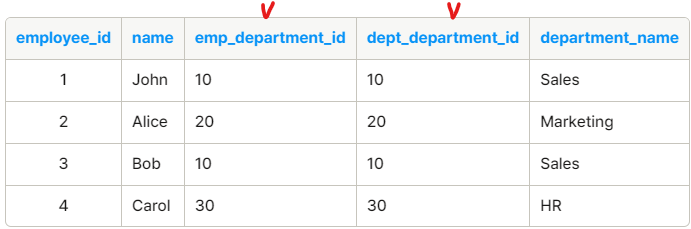
2) 자연 조인 ( Natural Join )
- 동일한 타입과 이름을 가진 컬럼을 조인 조건으로 이용하는 조인을 간단히 표현하는 방법
- 반드시 두 테이블 간의 동일한 이름, 타입을 가진 컬럼이 필요
- 조인에 이용되는 컬럼은 명시하지 않아도 자동으로 조인에 사용
- 동일한 이름을 갖는 컬럼이 있지만 데이터 타입이 다르면 에러 발생
- 두 테이블이 갖는 공통 컬럼에 대해 Inner Join은 별개의 컬럼으로 나타내지만, Natural Join은 하나의 컬럼으로 나타냄
- 예시

3) 전체 외부 조인 ( Full Outer Join )
- 좌측 테이블과 우측 테이블의 데이터를 모두 읽어 중복 데이터는 삭제한 Join 결과 반환
4) 왼쪽 외부 조인 ( Left Outer Join )
- 좌측 테이블 기준으로 일치하는 행만 결합하고, 일치하지 않는 부분은 NULL로 채움
5) 오른쪽 외부 조인 ( Right Outer Join )
- 우측 테이블 기준으로 일치하는 행만 결합하고, 일치하지 않는 부분은 NULL로 채움
6) 곱집합 ( Cross Join )
- 두 테이블 데이터의 모든 조합을 반환
- 조인 조건이 없는 조인
서브쿼리
SELECT문 안에 다시 SELECT문이 기술된 형태의 쿼리
종류
1) 스칼라 서브쿼리
- SELECT 절 안에 서브쿼리가 들어있는 형태
- 반드시 단일행이거나, SUM / COUNT 등의 집계합수를 거친 단일 값이 리턴되어야 한다.
- 예시
SELECT
employee_id,
name,
department_id,
salary,
(SELECT department_name
FROM departments
WHERE departments.department_id = employees.department_id) AS department_name
FROM
employees;
2) 인라인뷰 서브쿼리
- FROM절 안에 서브쿼리 존재
- 서브쿼리의 결과는 반드시 하나의 테이블로 리턴되어야 한다.
- 예시
SELECT
e.employee_id,
e.name,
e.department_id,
e.salary
FROM
employees e,
(SELECT AVG(salary) AS avg_salary
FROM employees) AS avg_salaries
WHERE
e.salary > avg_salaries.avg_salary;
3) 중첩 서브쿼리
- WHERE절 안에 서브쿼리 존재
- 단일행 서브쿼리 연산자 : >, >=, <, <=, = 등
- 다중행 서브쿼리 연산자
| 연산자 | 설명 |
| IN | 서브쿼리의 결과 값을 포함하고 있으면 출력 |
| EXISTS | 서브쿼리 결과 값의 행 존재 여부를 확인하여 출력 |
| ANY ( SOME ) | 서브쿼리 결과 값이 여러 개 나온 경우, 서브쿼리의 결과 값이 하나라도 만족하면 출력 |
| ALL | 서브쿼리 결과 값이 여러 개 나온 경우, 서브쿼리의 결과 값이 모두 만족하는 값을 출력 |
저장 프로시저
- 일련의 쿼리를 마치 하나의 함수처럼 실행하기 위한 쿼리의 집합
- 데이터베이스에 대한 일련의 작업을 정리한 절차를 관계형 데이터베이스 관리 시스템에 저장한 모듈
- 리턴값이 없거나 하나 또는 여러 개의 리턴 값을 가질 수 있다.
- 구조
CREATE OR REPLACE PROCEDURE 프로시저명
( 변수1 IN 변수타입, 변수2 OUT 변수타입, 변수3 IN OUT 변수타입... )
IS
변수처리부
BEGIN
처리내용
EXCEPTION
예외처리부
END;
트리거
- 테이블에 대한 이벤트에 반응해 자동으로 실행되는 작업 ( 연쇄반응 )
- 특정 테이블에 INSERT, DELETE, UPDATE와 같은 DML문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램
병행제어
여러 트랜잭션들이 동시에 실행되면서도 데이터베이스의 일관성을 유지할 수 있게 하는 기법
동시에 여러 개의 트랜잭션을 병행 수행할 때, 트랜잭션들이 DB의 일관성을 파괴하지 않도록 트랜잭션 간의 상호작용을 제어하는 것
목적
- 데이터베이스 공유도 최대화
- 응답시간 최소화
- DB 일관성 유지
병행제어를 제대로 관리하지 않았을 때 발생하는 문제점
1) 갱신 분실 ( Lost Update )
- 두 개 이상의 트랜잭션이 같은 자료를 공유하여 갱신할 때 갱신 결과의 일부가 없어지는 현상
2) 비완료 의존성 ( Uncommitted Dependency )
- 하나의 트랜잭션 수행이 실패한 후 회복되기 전에 다른 트랜잭션이 실패한 갱신 결과를 참조하는 현상
3) 모순성 ( Inconsistency )
- 두 개의 트랜잭션이 병행수행될 때 원하지 않는 자료를 이용함으로써 발생하는 문제
- 갱신 분실과 비슷해보이지만, 여러 데이터를 가져올 때 발생하는 문제
4) 연쇄 복귀 ( Cascade )
- 병행수행된 트랜잭션들 중 어느 하나에 문제가 생겨 Rollback하는 경우 다른 트랜잭션도 함깨 Rollback되는 현상
병행제어 기법
1) 로킹 ( Locking )
- 트랜잭션이 어떤 데이터에 접근하고자 할 때 로킹 수행
- 로킹이 되어 있는 데이터에는 다른 트랜잭션이 접근할 수 없음
- 트랜잭션은 로킹이 되어있는 상태에서만 연산 수행
| 구분 | 로크 수 | 병행성 | 오버헤드 |
| 로킹 단위가 크면 | 적어짐 | 낮아짐 | 감소 |
| 로킨 단위가 작으면 | 많아짐 | 높아짐 | 증가 |
2) 2단계 로킹 규약
- Lock과 Unlock이 동시에 이루어지면 일관성이 보장되지 않으므로, Lock / Unlock만 가능한 단계를 구분
- 확장단계 : 새로운 Lock는 가능하고, Unlock은 불가능하다.
- 축소단계 : Unlock은 가능하고, 새로운 Lock은 불가능하다.
3) 타임스탬프
- 데이터에 접근하는 시간을 미리 정해서 정해진 시간의 순서대로 데이터에 접근하여 수행
- 직렬가능성을 보장
- 교착상태가 발생하지 않는다.
- 연쇄 복귀를 초래할 수 있음
4) 낙관적 병행제어
- 트랜잭션 수행 동안은 어떠한 검사도 하지 않고, 트랜잭션 종료 시에 일괄적으로 검사
- 트랜잭션 종료 시에 동시성을 위한 트랜잭션 직렬화가 검증되면 일시에 DB로 반영
5) 다중 버전 병행제어
- 여러 버전의 타임스탬프를 비교해 스케줄상 직렬가능성이 보장되는 타임스탭프를 선택
- 충돌이 발생할 경우 복귀 수행
회복
트랜잭션들을 수행하는 도중 장애로 인해 손상된 데이터베이스를 손상되기 이전의 정상적인 상태로 복구시키는 작업
- Undo : 트랜잭션 로그를 이용하여 오류와 관련된 모든 변경을 취소하여 복구 수행
- Redo : 트랜잭션 로그를 이용하여 오류가 발생한 트랜잭션을 재실행하여 복구 수행
- 로그 파일 : 트랜잭션이 반영한 모든 데이터의 변경사항을 데이터베이스에 기록하기 전에 미리 기록해두는 별도의 파일
회복 기법
1) 로그 기반 회복 기법
- 지연갱신 회복 기법
- 트랜잭션의 부분 완료 상태에선 변경 내용을 로그 파일에만 저장
- 커밋이 발생하기 전까지 데이터베이스에 기록하지 않음
- 중간에 장애가 발생하더라도 데이터베이스에 기록되지 않았으므로 Undo가 필요 없음
- 즉시갱신 회복 기법
- 트랜잭션 수행 도중에도 변경 내용을 즉시 데이터베이스에 기록
- 커밋 발생 이전의 갱신은 원자성이 보장되지 않는 미완료 갱신이므로 장애 발생 시 Undo 필요
2) 검사점 회복 기법
- 체크포인트 회복 기법
- 장애 발생 시 검사점 이전에 처리된 트랜잭션은회복에서 제외하고 검사점 이후에 처리된 트랜잭션은 회복 작업 수행
3) 그림자 페이징 회복 기법
- 데이터베이스 페이지의 변경 사항을 직접 수정하지 않고, 변경 사항을 반영한 새로운 페이지를 별도로 작성
4) 미디어 회복 기법
- 디스크와 같은 비휘발성 저장 장치가 손상되는 장애 발생을 대비한 회복 기법
5) ARIES 회복 기법
| 단계 | 설명 |
| 분석단계 | 붕괴가 발생한 시점에 REDO가 시작되어야 하는 로그의 위치 설정 |
| REDO 단계 | REDO 시작 위치의 로그로부터 로그가 끝날 때 까지 REDO 수행 REDO된 로그 레코드의 리스트를 관리하여 불필요한 REDO 연산이 수행되지 않도록 한다. |
| UNDO 단계 | 로그를 역순으로 읽으면서 진행 트랜잭션의 연산을 역순으로 UNDO |
ETL
기존의 원천 시스템에서 데이터를 추출 ( Extraction )하여 목적 시스템의 데이터베이스에 적합한 형식과 내용으로
변환 ( Transformation )한 후 목적 시스템에 적재 ( Loading ) 하는 일련의 과정
데이터 웨어하우스 : 기업 전반의 데이터를 통합하여 저장하는 대규모 데이터베이스 시스템
데이터 마트 : 특정 부서나 팀의 요구에 맞춘 소규모 데이터 웨어하우스
데이터 마이닝 : 대규모 데이터에서 유용한 패턴이나 규칙을 발견하는 과정으로, 데이터 웨어하우스에 저장되 데이터를 분석하여 의미 있는 정보를 도출
데이터 품질 관리 대상 : 데이터 값 - 데이터 구조 - 데이터 관리 프로세스
'정보처리기사' 카테고리의 다른 글
| 모의고사 -1 (0) | 2024.06.18 |
|---|---|
| 운영체제 -1 (0) | 2024.06.17 |
| 데이터베이스 구축-3 (1) | 2024.06.13 |
| 데이터베이스 구축-2 (0) | 2024.06.13 |
| 데이터베이스 구축-1 (1) | 2024.06.13 |